Deep Learning is data hungry and data augmentation has proven extremely useful in improving model generalization performance in medical image analysis tasks; it is very difficult to generalize with fewer data; where in our project, we discuss whether a patient has monkeypox or not with very limited data. There are proven methods where increasing amounts of training samples are valuable for the performance of model in generalization such as organ-at-risk (OAR) segmentations. So, it is very important to provide challenging augmentation to the model to increase the data diversity. In this project, we are trying to solve a task that is to classify if the sample has monkeypox or not with very less data by analyzing with different data augmentation techniques. Our objective is to employ variational autoencoder (VAE) and generative adversarial network (GAN), to generate new samples, which will enrich the number of samples in our training strategy.
We have setup the baselines using conventional augmentation techniques and tried to add probabilistic machine learning based methodologies GAN and VAE to generate more diversified samples. We compared the baseline augmentation methods with probabilistic approaches and compare their performance on same model architectures (ResNet34 and ResNet50). We can see significant improvements to the performance on held-out data when probabilisitc models are used for increasing the sample space.
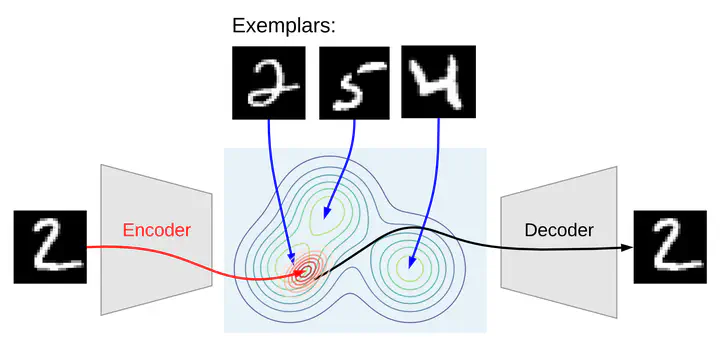
Image credit: (https://exemplar-vae.github.io/exemplar-vae-generation.svg)
Abu Zahid Bin Aziz
Research Assistant
My research interests include deep learning, medical imaging and bioinformatics.
